
안녕하세요! 저번 포스팅에서 R의 기본 자료형에 대해서 알아보았습니다!
numeric, character, logical, complex, raw 등등을 같이 공부해봤습니다!
그러면 이번 포스팅부터 본격적으로 데이터 타입에 대해서 배워볼텐데
정말 아무리 강조해도 지나치지 않을 중요한 시간이라고 할 수 있겠네요!
먼저 R에서 제공하는 여러 데이터 타입에 대해 표 형식으로 preview 해볼까요?
R의 기본 데이터타입은 vector를 포함하여 다음과 같은 다양한 데이터 타입을 제공하고 있습니다.

R에서 제공하는 데이터 타입이라는 것은 실제 세계의 자료를 표현하는 방법입니다.
즉, 실제 세계의 자료를 표현할 수 있게끔 R에서 어떤 형태들을 지원해주냐는 것이죠.
예를 들어 여러 개의 숫자를 이용해서 평균을 구한다고 하면 여러 개의 숫자를 어떻게 컴퓨터가 이해하게 만들 수 있을까요? 혹은 표 형태를 이용해서 통계처리를 한다 하면 그 표 형태를 어떻게 컴퓨터가 이해하게 할 것인가요?
R에서 이런 여러 개의 숫자를 담은 데이터 혹은 표 형식의 데이터들을 어떻게 지원하는지 알아야합니다. 그리고 바로 이것이 데이터 타입이라고 할 수 있는 겁니다.
R은 기본적으로 통계를 위한 언어이다 보니까 통계에 관련된 일련의 데이터, 표 형태의 데이터를 굉장히 쉽게 처리하도록 만들어져 있는데요.
이제부터 그러면 데이터 타입을 하나씩 살펴보도록 하죠!
위의 6가지 데이터 타입을 모두 다루어 볼 예정인데 오늘은 그 첫 시간으로 Vector(벡터)에 대해 다루겠습니다.
Vector(벡터)
벡터는 같은 자료형을 가진 여러 개의 값으로 구성된 1차원의 데이터입니다.
같은 자료형이어야 한다는 것을 명심해주세요.
이 정의가 어렵다면 엑셀을 생각해보면 되는데, 엑셀에서 한 열에 들어 있는 여러 행들이라고 생각하면 됩니다.
예시를 봅시다.

이는 A라는 열에 6개의 실수의 값들이 들어있네요.
이렇게 벡터를 생각하면 되는데 이 엑셀의 예에서도 같은 자료형의 값들만 넣었음을 꼭 명심합시다.
벡터를 사용하면 여러 개의 연속적인 데이터를 한 번에 변수 하나로 처리할 수 있으니 정말 간편합니다.
R은 기본 자료형이 scalar(값이 하나 인 것)이 아니라 vector(여러 개 값의 모음)입니다.
왜 그럴까요? R은 통계처리를 위한 언어이다 보니까 통계처리가 필요 없는 하나의 값은 불필요하겠죠!
그래서 여러 값을 가지고 있는 vector가 기본 자료형이 되는 것입니다.
그래서 R은 기본적으로 여러 개의 값을 받아들인다고 가정하고 프로그래밍을 할 수 있게 되어 있다는 점! 알아두세요!
그러면 이제 벡터를 생성해보도록 하죠!
벡터를 생성하는 방법에는 여러 가지가 있는데요!
먼저 vector()라는 함수를 사용하는 방법이 있습니다!

이렇게 함수와 인수를 조합하면 되는데요!
벡터에는 같은 자료형만 넣어야 하므로 먼저 어떤 자료형을 넣을 것인지 (numeric인지 character인지 등등) 지정해주고 길이는 얼마로 할 것인지, 즉 몇 개의 데이터를 집어넣을 것인지 입력해주면 됩니다!
예를 볼게요

빈 벡터를 생성하고 싶다면 밑처럼 코딩해주시면 됩니다!

이렇게 vector()함수를 사용하는 것이 너무 길다면 좀 간단하게도 사용할 수 있는데요!

이렇게 말이죠! (integer는 numeric에 포함됩니다!)
외에도 c() 함수를 사용할 수 있는데요
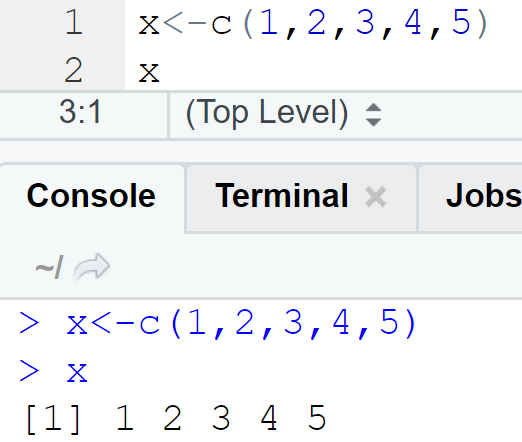
이렇게 말이죠!
그런데 1,2,3,4,5는 수열이잖아요! 이런 경우에는
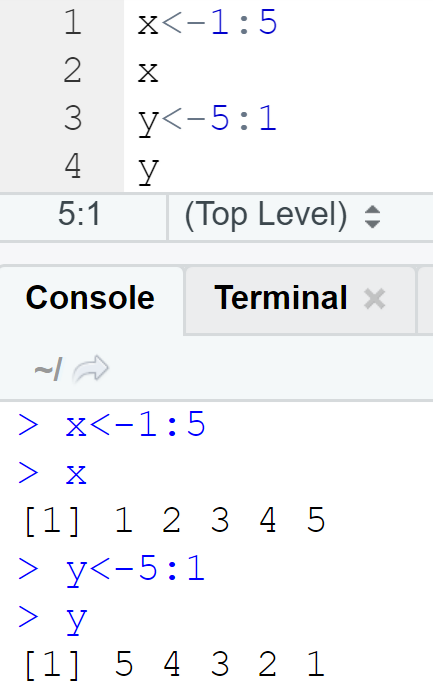
이렇게도 가능합니다!
이렇게 “:”만으로도 가능하지만 수열을 생성하면서 인수를 활용해 더 세밀한 데이터를 얻고 싶으면
seq()이라는 함수와 rep()라는 함수가 있는데요!
알아보죠!
seq()함수에는 어느 숫자부터 시작할 것인지(from=), 어느 숫자까지 할 것인지(to=), 얼만큼의 간격으로 할 것인지(by=), 처음숫자부터 끝 숫자 사이에 몇 개의 수를 생성할 것인지(length.out=) 등의 인수가 있습니다!
예시를 보면 이해가 쉬워질 거에요!

이렇게 from, to, by는 생략할 수도 있습니다.
그럼 이제 rep()함수에 대해 알아볼게요
rep()함수에는 개별 원소를 반복해주는 ‘each=인수’, 데이터전체를 반복하는 ‘times=인수’, 생성될 데이터의 개수를
지정해주는 ‘length.out=’ 인수가 있습니다.

위의 예제에 length.out 인수를 적용하면

이렇게 8개만 출력해줍니다!
그런데 여기서 꼭 짚고 넘어가야 할 부분이 있는데요!
벡터 생성 시에 문자, 숫자를 섞어서 할당할 때는 문자로 변환됩니다. 앞서도 계속 강조했듯이 벡터는 하나의 자료형만 가질 수 있기 때문이죠.

이렇게 벡터를 생성하는 여러 가지 방법을 보았습니다!
그러면 이제 벡터에 원소를 추가하는 법에 대해 알아볼게요! 벡터에 원소를 추가하고 싶을 때는 꼭 있겠죠?
벡터에 원소를 추가하는 함수는 append() 함수입니다.
이용할 벡터를 입력하고 추가할 원소를 입력합니다. 그리고 위치를 정해주고 싶다면 2라고 쓰면 원래 벡터의 두번째
원소 뒤에, 3이라고 쓰면 원래 벡터의 세번째 원소 뒤에 추가할 원소가 들어가게 됩니다. 예시를 들어볼게요!

다음으로는 벡터의 개별 원소들에 이름을 붙이는 함수에 대해 알아볼게요!
바로 names함수입니다.

이렇게 names함수를 이용하면 벡터의 원소들에 이름이 붙게 됩니다!
이제 마지막으로 벡터의 원소에 접근하는 법! 벡터 원소 추출[subsetting]에 대해 알아보겠습니다!
벡터의 개별 원소 값들은 어떻게 불러올 수가 있을까요?
일단 벡터를 추출할 때는 “[ ]” 이 연산자를 사용합니다.
원소의 번호는 첫 번째 원소부터 1,2,3,… 이렇게 매겨집니다.
[ ]안에 들어갈 수 있는 것은 numeric이나 logical 자료형입니다. 그리고 앞서서 vector에 이름을 붙여주는 함수에 대해서 배웠는데 vector에 이름을 붙여주었으면 그 이름을 이용해서도 추출할 수도 있어요!
먼저 [ ]안에 양의 정수를 넣어서 추출해보도록 할게요!

이제는 음의 정수를 넣어서 추출해볼게요!

이제 논리값으로 추출해볼게요!

이제는 원소의 이름으로 추출해볼게요!

원소 추출 후 다른 값으로 대체할 수도 있는데요!
예시를 보여드릴게요

이렇게 해서 오늘 포스팅에서는 벡터에 대해 알아보았습니다! 다음 포스팅에선 팩터와 매트릭스에 대해 배워보겠습니다!!
'Data analysis story' 카테고리의 다른 글
| [Python] 내장함수-print, input, int, float, str, abs, round, pow 함수 (0) | 2020.04.10 |
|---|---|
| [Python] 파이썬의 변수, 상수 (1) | 2020.04.09 |
| [R프로그래밍] R의 기본자료형 (1) | 2020.04.09 |
| [R프로그래밍] 기본 연산, 기본 문법 (0) | 2020.04.08 |
| [엑셀] 실무에서 자주 사용하는 엑셀 함수 익히기 ⑥ (TODAY, DATE, YEAR, MONTH, DAY, WEEKDAY, DEATEDIF, NOW, TIME, HOUR, MINUTE, SECOND 함수) (0) | 2020.03.03 |



