
안녕하세요! 여러분!!
오늘은 저번 두개의 포스팅에 걸쳐 다뤘던! apply 계열 함수에 이어
데이터분석을 위한 R의 내장 함수 중 중요한 aggregate 함수에 대해서 알아보겠습니다!!
apply 함수를 꼭 숙지하시고 오세요!
먼저 aggregating을 왜 하는지에 대해서 알아봅시다!
먼저 aggregating을 설명하기 위해 사용할 데이터를 소개할게요!
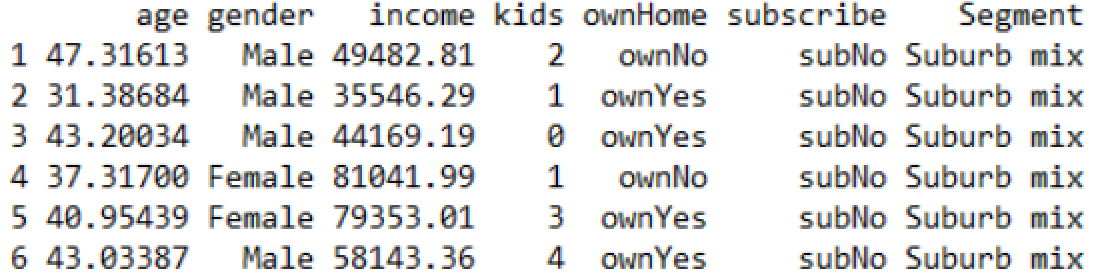
이 데이터들을 보면
나이, 성별, 수입, 자녀 수, 자가 여부, 구독 여부, Segment 등등에 대한 데이터가 나와있는데요!
이 데이터는 한 회사의 케이블 TV에 관한 데이터라고 합니다!
그러면 이 케이블 TV 데이터를 통해서 이 회사가 얻고 싶은 정보가 무엇일까요?
어떤 사람들이 우리의 케이블 TV를 구독하는지 궁금하지 않을까요?
예를 들어서 소득 수준에 따라 케이블 TV 구독 여부가 다를까,
혹은 자녀의 수에 따라서 구독 여부가 달라질까, 또는 성별에 따라 구독 여부가 달라질 까
등등이 궁금하겠죠!
그러면 이런 정보들을 얻기 위해
케이블 TV를 구독한 사람과 구독하지 않은 사람들을 따로 묶어서 봐야겠죠!
구독한 사람은 subscribe라는 변수의 값이 ‘subYes’이고
하지 않은 사람은 이 변수의 값이 ‘subNo’입니다!
이는 factor, 즉 범주형 변수이죠!
따라서 범주형 변수에 따라 subscribe가 subNo인 경우의 소득 평균, subYes인 경우의 소득 평균을 구하면
소득 수준에 따라 케이블 TV의 구독 여부가 다른지 알 수가 있겠죠!
어떤 기준을 가지고 묶어서 분석할 수 있다는 것이죠!
그리고 그것이 필요한 상황이 굉장히 많구요!
이렇게 데이터들을 분석하다 보면
최종적으로 age, gender, income, kids, ownHome 등등의 변수 중
어떤 변수가 우리 회사 케이블 TV의 구독 여부에 가장 큰 영향을 미치는지 찾아낼 수가 있겠죠!
이것이 바로 데이터 분석을 하는 과정입니다
특정 집단들 사이에 어떤 차이가 있을까? 혹은
특정 변수들끼리 어떤 관련이 있을까? 등등을 알고 싶을 때 바로 이 aggregate 함수를 사용합니다.
이런 aggregating을 하는 가장 간단한 예제를 저번 시간에 tapply 함수를 통해 알아보았었는데요
오늘은 aggregate 함수를 통해 좀 더 체계적으로 공부해보도록 하죠!

이 데이터에서 subscribe 변수가 subNo인 income의 평균과
subYes인 income의 평균을 구하려면
우리는 이때까지 어떻게 했었죠?
[ ] 연산으로 추출을 했었죠?
이렇게요!
앞의 데이터프레임을 seg.df 변수에다 할당하고 이 변수를 attach한 후
(코드: attach(seg.df) )

income의 값들을 모아 놓은 것은 벡터니까 벡터 추출 연산인 []를 사용하면 되잖아요!
그러면 구독을 한 사람의 소득 평균과 하지 않은 사람의 소득 평균을 비교할 수 있었습니다!
또한 더 나아가서 Segment가 Suburb mix이면서
subscribe가 subNo인 사람들의 소득 평균을 구하고 싶으면

이렇게 &를 이용해서 조건을 추가해주면 됐었습니다!
아니면 저번 시간에 배운 apply 함수를 통해서도 다양한 정보들을 얻을 수 있는데요

이렇게 seg.df라는 데이터프레임의 첫번째, 세번째, 네번째 변수
(age, income, kids[숫자인 데이터타입의 변수들만 가지고 왔죠?])들을 가지고 와
열 별로 평균을 적용할 수 있는 것이죠
혹은 subscribe가 “subNo”인 나이, 소득, 자녀 수의 평균을 구하고 싶다면

이렇게 하면 되겠죠!
그런데 가만히 보면 데이터프레임 이름을 attatch도 해야 하고 코드가 깔끔하지도 않습니다.
구독 여부에 따른 소득 수준을

이렇게 각각 타이핑해서 구했는데
각각 만들었기 때문에 다른 변수에 저장해야 하므로
비교하기도 불편하구요!
subscribe라는 ‘기준’을 주고 ‘목표’인 income을 알기 위해
한번에 적용할 수 있는 함수는 없을까요?
그런 함수 중 대표적인 함수가 ‘by’라는 함수입니다.
사용방식은
by(목표 변수, 기준변수, 함수)
입니다.
Segment별로 income함수를 평균 내라는 것이죠
결과는

이렇게 출력되며 list로 반환하는 것을 알 수 있습니다.
혹은 이렇게

Segment와 subscribe의 조합을 목표 변수로 삼을 수도 있습니다.
이때는 list로 만들어 준 후 집어넣어야겠죠!

결과는 이렇게 나옵니다!
하지만 by함수는 결과를 list로 돌려주기 때문에 바로 가져다 쓰기는 불편합니다
그래서 aggregate라는 함수가 있습니다!
aggregate 함수는 굉장히 많이 쓰이는데요!
aggregate(목표 변수, 기준 변수, 함수)
이렇게 사용합니다!

단, 기준 변수를 사용할 때
list(기준 변수)로 사용해야 한다는 것이 by와 다른 점이겠네요!
그리고 “aggregate 함수는
결과 값을 데이터프레임으로 돌려줍니다.”
그렇기 때문에 데이터프레임으로 나온 결과 값에서
열을 이용해 데이터들에 보다 쉽게 접근할 수 있는 것이지요!
그래서 by보다는 aggregate를 쓰는 것을 선호합니다.
하지만 조금 불편한 것은
위의 결과 값을 보면

이렇게 열 이름이 임의로 주어진 다는 것입니다.
이를 해결해줄 방식으로
포뮬러 방식이 있습니다.
포뮬러를 사용하면 훨씬 효과적이죠.

이렇게 써주면
열 이름이 임의로 주어지지 않고 income, Segment와 같이 정확히 주어집니다.
Segment말고도 기준 변수를 더 주고 싶을 때는

이렇게 사용하면 되고 결과 값은

이렇게 깔끔하게 나오게 됩니다!!
이렇게 보니 aggregate 함수는 아주 강력한 함수가 아닐 수 없겠죠??
by나 aggregate 이외에도 데이터분석에 많이 쓰이는 함수들이 있습니다.
1. cut 함수
먼저 cut 함수인데요!
cut 함수는 연속형 변수를 특정구간으로 구분하여 명목형 변수로 변환해줍니다!
cut(데이터, breaks=구간수, labels=구간 이름)
이렇게 사용합니다.
앞서 aggregate 함수를 이용해서 만든

이 데이터에서 income이라는 연속형 변수를 특정 구간으로 구분하려고 할 때
예를 들어

이렇게 바꿀 때 사용하는 함수가 바로 cut함수인 것입니다!
코드는

이렇게 짜주면 위와 같은 결과가 나옵니다!!
2. grep 함수
그리고 두번째로 grep함수를 소개하겠습니다!
grep함수는 데이터 내에서 특정 패턴을 찾는데 사용합니다.
grep(“패턴”,데이터)
이런 형식으로요!
예를 볼까요?

ap이 포함된 위치를 잘 반환하네요!
위치가 아닌 그 값을 반환 받고 싶다면

value=T라는 인수를 넣어주면 된답니다!
이 grep이라는 함수를 소개한 이유는
공통된 패턴을 가진 자료들의 위치를 찾아서
그 위치 값을 활용해 데이터를 일괄 변환할 때 유용하게 사용되기 때문입니다!
3. gsub 함수
마지막으로 소개할 함수는 gsub함수입니다.
gsub함수는 데이터에 포함된 특정 패턴을 찾아서 수정합니다.
gsub(“수정할 패턴”,”수정할 내용”,데이터)
이런 형식으로 사용되죠!
예를 들어
처음에 seg.df라는 변수에 저장한 데이터

여기서
Segment의 값들에 존재하는 공백을 없애주고 싶다면


이렇게 공백이 없어져서 결과가 나오게 된답니다!!
오늘은 이렇게 해서 aggregate함수와 cut, grep, gsub 함수에 대해서 살펴봤습니다!!
데이터 분석을 위해 모두 필요한 함수들이니
꼭 열심히 공부하도록 합시다!!



